
Synthèse Bibliographique 5IF
Marie-Hélène Balland
Alexandre Delavanne
David Fortino
Sylvie Loore
février 1999
Sommaire
1 Introduction *
2 La numérisation et le format des documents *
2.1 La récupération des documents *
2.1.1 Récupération des documents électroniques *
2.1.2 Numérisation des documents *
2.2 Traitements intermédiaires des documents *
2.2.1 La reconnaissance optique de caractères *
2.2.2 Détermination de la structure d’un document *
2.3 Les formats de stockage *
2.3.1 Les documents textes *
2.3.2 Les images *
2.3.3 Les compléments multimédias *
3 Classification, indexation et recherche d’information *
3.1 La classification des documents *
3.2 L’indexation *
3.3 La recherche de documents *
4 Architecture *
4.1 Les différentes technologies *
4.1.1 Le problème de l’interopérabilité *
4.1.2 L’apport de CORBA au problème des bibliothèques virtuelles *
4.1.3 Les architectures à plusieurs couches *
4.1.4 Les systèmes de gestion de documents *
4.2 Composants particuliers *
4.2.1 Le protocole Z39.50 *
4.2.2 Proxy et Infobus *
4.2.3 Le payement électronique *
4.3 Étude de cas *
4.3.1 Bibliothèque Nationale de France *
4.3.2 Université du Kansas *
4.3.3 Doc’Insa *
4.3.4 Université de Stanford *
4.4 Mesures du succès des architectures *
5 Aspect juridique *
5.1 L’Existant *
5.2 Les Positions de l’ECUP *
5.3 Les solutions actuelles *
6 Discussion sur l’aspect social *
6.1 Utilisateurs *
6.2 Bibliothécaires *
7 Conclusion *
8 bibliographie *
Aujourd’hui avec l’émergence des services via le Web on voit peu à peu apparaître le principe de Bibliothèque Virtuelle. Une bibliothèque virtuelle est une possibilité offerte de consulter des millions de pages en ligne [ROSNAY98] avec l’aide de logiciels de navigation et d’agents intelligents adaptés à des recherches personnalisées, mais c’est aussi le risque d’un espace froid et vide privé du lien affectif et de la convivialité humaine.
La mise en place d’une bibliothèque virtuelle comporte plusieurs aspects : tout d’abord l’aspect bibliothèque numérique dans lequel tous les documents doivent être au format numérique, correctement classés et indexés pour améliorer leurs recherches. Puis, l’aspect Virtuel c’est à dire l’accès à distance aux documents avec l’utilisation d’architectures informatiques adaptée. Enfin, le dernier point et non le moindre concerne les problèmes de droits d’auteurs pour la diffusion de documents électroniques ainsi que l’aspect social d’un tel système.
Dans une première partie, sera présentée la phase de numérisation des documents : le mécanisme d’obtention des documents et le format de stockage.
Dans une seconde partie, le mécanisme d’indexation des documents sera détaillé ainsi que la recherche de documents. On s’attardera à présenter le principe des méta — données pour l’indexation, et les exigences en matière de recherche d’informations.
Puis dans une troisième partie, il sera présenté les différentes architectures des bibliothèques virtuelles avec les technologies utilisées et le détail de quelques composants particuliers. En appui de cette partie, différentes études de cas seront présentées.
Enfin dans une dernière partie, les problèmes juridiques, en particulier le problème du droit d’auteurs, seront évoqués.
En conclusion, l’impact de ce type de bibliothèque sur la société sera exposé.
Tout au long de ce rapport, nous nous efforcerons de traiter l’ensemble de ces aspects afin d’avoir une vue complète sur les bibliothèques virtuelles.
La récupération des documents peut s’effectuer sous deux formes différentes. La première est de demander au créateur du document une version électronique et la seconde de numériser les documents afin de les informatiser.
2.1.1 Récupération des documents électroniques
Dans la grande majorité, les auteurs de thèses, entre autres, réalisent leurs documents sur ordinateur [HUNEAU97]. Les traitements de textes principalement utilisés sont Microsoft WinWord pour Macintosh (26%), Microsoft WinWord pour PC (67%) et TeX (7%). Il se peut que ces documents ne contiennent pas toutes les informations concernant le document original. En effet, certaines personnes ne disposant pas du matériel nécessaire, n’intègrent pas les images sous format numérique dans le document électronique, mais en collant la photo ou en dessinant le schéma. Pour ce genre de document (relativement rares), il est nécessaire de disposer d’un scanner afin de pouvoir les intégrer.
La numérisation des documents peut parfois poser des problèmes. En effet, suivant le type de document, il y a des contraintes à respecter. Pour la majorité des documents, il est nécessaire de choisir la résolution et le nombre de couleurs et souvent 2 couleurs (noir et blanc) seront amplement suffisantes. Par contre, pour des documents du genre tableaux ou même livres anciens colorés, plus de couleurs seront nécessaires.
La résolution et le nombre de couleurs, pour les documents anciens, dépend du type de ces documents [GLAMIN98]. Pour les manuscrits, le contenu est plus important que les détails visuels du document, il n’est donc pas nécessaire d’avoir une résolution et un nombre de couleurs important (100 à 200 points par centimètres, 16 à 32 couleurs suivant si le texte est petit ou non). Par contre, les photos où les documents dont l’aspect visuel est important doivent être numérisés avec une résolution supérieure (2500 * 3000 pixels avec 16 millions de couleurs). Pour leur diffusion sur Internet, il est nécessaire de réduire leur taille originelle (20 Mo) à environ 150 à 250 Ko. Pour cela, la résolution de 1000*1000 est choisie avec des algorithmes de compression.
Pour les livres anciens, la numérisation peut poser quelques fois des problèmes du fait de leur fragilité. Le problème est résolu grâce à des stations de numérisation spécialisées [FP98]. Celles-ci sont prévues pour éviter de casser la tranche du livre et de respecter le document pour le garder intact.
Suivant le type de document numérisé, il sera nécessaire d’effectuer une reconnaissance optique des caractères afin de transformer le document résultant de la numérisation en document texte. Cette possibilité n’est pas une obligation, mais pour permettre au moteur de recherche d’effectuer une indexation automatique, cette étape devient inévitable. Pour les documents anciens, la reconnaissance optique n’est pas envisageable et se fera manuellement.
Il existe de nombreux produits permettant de réaliser cette reconnaissance optique et ceux-ci sont de plus en plus performants. Par exemple, OmniPage Pro [KRIM98] permet maintenant de traiter les documents en couleur. De plus, la plupart des produits permettent de conserver la mise en page, la police de caractère, la taille, … Ceci permet alors de fournir un document électronique reflétant exactement l’original.
Le processus de reconnaissance se découpe en de nombreuses tâches distinctes [SRILAM94]:
Suivant le format de stockage choisi (voir plus loin), il est nécessaire de déterminer la structure du document [FURUTA94]. La consultation d’un document devient tout de suite beaucoup plus aisée, lorsqu’il est possible à partir du sommaire d’accéder directement à la page souhaitée. De même, il serait impensable de visualiser un document sans pouvoir ressortir de celui-ci les éléments importants comme les titres, sous titres, paragraphes. De même les liens hypertextes doivent pouvoir être retrouvés et traités comme tels et non comme une ligne de texte normale. Suivant le type de format de fichier retenu, la structure sera plus ou moins bien représentée. La structure (cf. figure 1) peut être représentée linéairement ou de façon hiérarchique. Il est bien évident que la consultation restera plus aisée avec une structure hiérarchique.
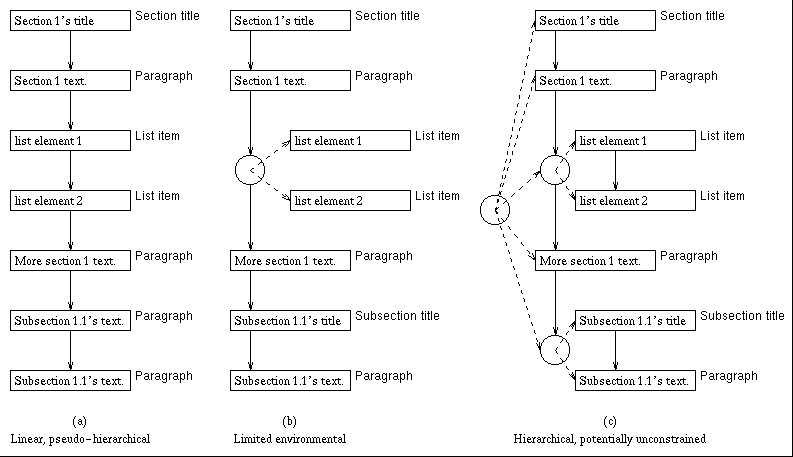
Figure 1 : structure possible d’un texte
Il existe de nombreux formats disponibles pour le stockage des informations. Entre autres :
Ce format de fichier est encore utilisé car il évite les conversions sous des formats plus complexes. Il pose toutefois des inconvénients pour la visualisation à l’intérieur d’un navigateur Internet.
Ce format est utilisé par Internet. Il est reconnu par tous les navigateurs, mais possède comme défaut d’offrir peu de possibilités de mise en page du fait de sa simplicité (on ne peut, par exemple, aligner un texte qu’à gauche, droite ou centrer. Il est impossible de le décaler de 2 cm de la marge sans compliquer le code de façon importante). Il permet de créer des liens entre plusieurs documents afin de faciliter la navigation. Il accepte les images et également des ajouts appelés Plug-In permettant d’augmenter ces capacités (Cette possibilité reste toutefois limitée du fait de sa complexité).
Il s’agit d’un tout nouveau format promis à un très bel avenir. Il n’est actuellement utilisé que ponctuellement du fait de sa jeunesse. Il a de nombreuses possibilités et correspond en fait à une importante extension de HTML et à une version simplifiée de SGML. Il a des possibilités de mise en page très importantes. XML, tout comme SGML, se compose de deux parties : le document et l’application (cf. SGML). L’application XML donne une sémantique au document.
Le format PDF a été créé dans le but de représenter fidèlement le document original tout en conservant une taille minimale. Actuellement, il peut être visualisé sur la quasi-totalité des plates-formes et peut également être imprimé (le résultat obtenu restant fidèle à l’original).
Ce type de fichier permet de gérer le plan du document (hiérarchique ou non), des liens internes, des images, des sons, … mais également des liens externes (internet).
Il est actuellement, pour les bibliothèques virtuelles, l’un des formats de fichier les plus utilisés avec SGML.
SGML a pour but de représenter la totalité des documents électroniques quelque soit l’évolution technologique et les nouvelles formes de documents pouvant apparaître. Pour cela, SGML sépare la structure logique (Document Type Definition : DTD) des documents de leur contenu.
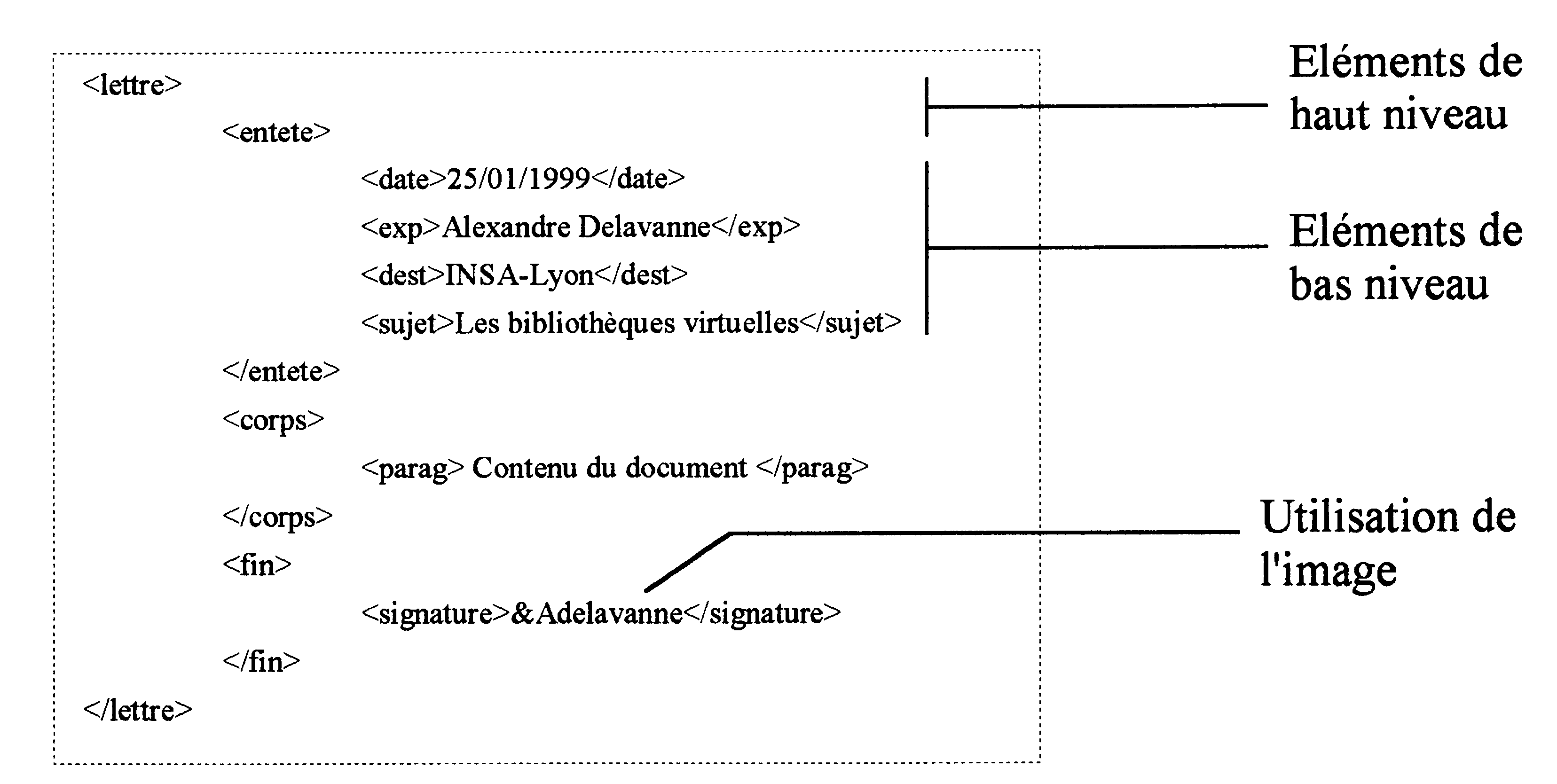
La DTD décrit les éléments pouvant être contenus dans un document et pour chacun de ces éléments, ceux qu’ils peuvent contenir avec leurs règles d’apparition (nombre d’occurrence : + (1,n), ? (0 ou 1), * (0,1, n) ). Elle décrit ainsi tous les éléments jusqu’au niveau le plus bas possible (cela peut être des données, ou même des images). Par exemple, une lettre (élément principal) peut contenir dans l’ordre une entête, un corps et une fin. La DTD décrira alors les éléments jusqu’au niveau le plus bas pouvant contenir la date, le paragraphe, une formule, une adresse d’expéditeur, de destinataire, …
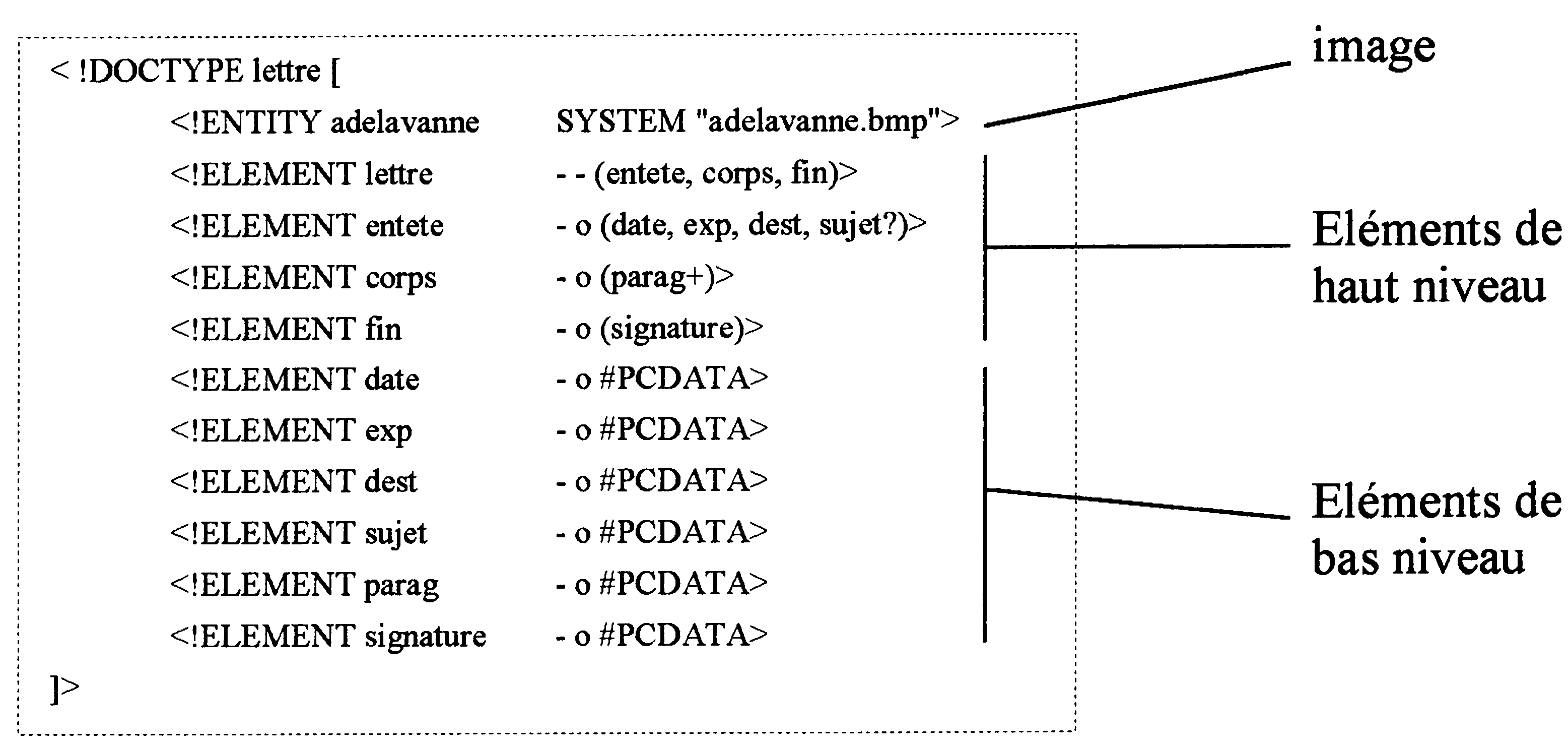
D’un autre côté, SGML fournit les instances se basant sur une ou plusieurs DTD. Ces instances contienne la description du contenu en utilisant les éléments décris dans la DTD. Par exemple :
Ce format est peu utilisé de nos jours. Il subsiste toutefois pour permettre la diffusion de documents techniques ou par exemples des chèques [SELNICK98]. L’avantage est qu’il permet de mettre rapidement à disposition ces documents sans passer par une analyse qui dans ce cas semble finalement inutile étant donné l’utilisation du contenu . Les liens entre les documents doivent être fournis par l’administrateur et un plug-in (ajout logiciel d’un explorateur Internet) permet de consulter aisément ces documents. Le seul point négatif de cette méthode est la taille de chacune des images qui, si on n’y prête pas attention, peut devenir très important.
Ce format d’image permet de stocker dans un emplacement moindre que les autres formats. Il compresse les images en supprimant les informations non indispensables pour l’œil. Il ne peut pas être utilisé lorsqu’il s’agit de tableaux numérisés où le moindre détail est très important. Du fait de la perte d’information, il ne sert pas pour la présentation mais pour les photos.
Ce format est le plus utilisé, car il compresse les images sans pertes. Il est surtout utilisé pour la présentation et les dessins. Il peut également être utilisé pour les photos, mais le format JPEG est plus intéressant.
Dans les bibliothèques numériques, les documents multimédias représentent une part moins importante. Pour la vidéo, le format le plus utilisé actuellement est le MPEG. Il se base pour les images sur le format JPEG. La vidéo requière toutefois, pour l’instant, des débits très important, ce qui est un frein pour son utilisation dans des bibliothèques virtuelles. En ce qui concerne le son, il existe différents formats de stockages comme wav, mp3, midi, … La quasi-totalité effectuent une compression. Les meilleures sont les compressions avec perte d’informations. Dans l’ensemble, tous les formats se ressemblent mis à part le format MIDI qui décrit exactement les instruments, les notes, … Il s’agit en fait d’une musique de synthèse dont la qualité est moindre que les musiques numérisées.
L’objectif principal d’une bibliothèque virtuelle est de permettre la consultation des documents numérisés (obtenus par les techniques présentées ci — dessus). Afin de proposer un service efficace, les documents numériques doivent être correctement classés (comme au sein d’une véritable bibliothèque), puis indexés afin de pouvoir être "consultés " par les moteurs de recherches. Les utilisateurs doivent pouvoir retrouver des documents aussi facilement qu’au sein d’une véritable bibliothèque.
Dans toutes les bibliothèques, les documents ne sont pas présentés en vrac mais sont correctement ordonnés afin d’en faciliter la gestion et la recherche.
Pour les bibliothèques virtuelles, on est dans la même situation : les documents numériques doivent aussi être correctement classés pour être bien gérés.
Dans les bibliothèques traditionnelles c’est la Classification Décimale de Dewey (CDD) qui est la plus couramment utilisée. Cette classification est aussi généralement celle utilisée pour les bibliothèques numériques.
La principe de la CDD est de découper l’information en différentes classes principales. Les classes principales [BACCON96] sont ordonnées par disciplines traditionnelles ou domaines d’études. Le principe fondamental de la CDD est le classement par discipline.
Elle répartit le savoir en dix classes principales qui réunissent la totalité des connaissances. Ces classes comprennent chacune dix divisions et chaque division comporte dix sections. Le premier chiffre des indices renvoie à la classe principale. Seul le premier chiffre est significatif dans cette liste. Les zéros servent à compléter la notation qui doit se composer de trois chiffres. (ex 100 représente la discipline philosophie, 300 la sociologie).
Chaque classe principale contient dix divisions, numérotées de O à 9, le deuxième chiffre désigne la division. Chaque division comporte dix sections numérotées de 0 à 9. Le troisième chiffre de chaque indice désigne la section. Un point décimal est inséré après le troisième chiffre. Après le point décimal, la division par dix continue jusqu’au degré de précision désiré.
Exemple : 312.5 correspond à un ouvrage de sociologie (on le sait grâce au 3), le 1 représente une première division (par exemple la sociologie de l’urbanisme), le 2 représente une section de la division précédente (par exemple pour préciser qu’il s’agit de l’urbanisme dans les pays d’Europe). le 5 de la partie décimale permet d’affiner la description en précisant par exemple qu’il s’agit de la France.
La CDD est une classification hiérarchique dans sa notation et dans sa structure. Dans une telle classification chaque document n’est référencé que dans une seule classe.
Cette classification a fait ses preuves, cependant son principal inconvénient est qu’un document n’est référencé qu’une seule fois, ce qui ne facilite pas toujours les recherches.
En effet nombreux sont les documents qui traitent de plusieurs sujets et il est parfois délicat de faire appartenir un document à une classe plutôt qu’à une autre [ALLEN95].
Dans certains cas on lui préfèrera la classification scientifique adoptée par ACM Computing Reviews, qui regroupe les documents par sujets. Un document pouvant traiter plusieurs sujets, on peut ainsi le retrouver à plusieurs endroits dans la classification. Ainsi on pourra atteindre un même document par différents chemins.
La classification des documents est essentielle pour la gestion de la bibliothèque virtuelle, mais elle peut aussi être utilisée lors de la recherche de document grâce au mécanisme d’indexation.
La phase d’indexation permet d’extraire les concepts des documents [FOUREL96]. Un document dans une bibliothèque virtuelle n’est considéré que comme un support qui véhicule de l’information. La phase d’indexation permet de capturer cette information et de la représenter sous forme d’un modèle : le modèle de document ou les méta — données. L’information capturée correspond au contenu sémantique du document et la représentation de ce contenu sémantique est appelée un index de document.
L’indexation des documents numériques consiste donc à fournir des informations utiles sur chaque document et ce dans le but d’en faciliter l’accès par les moteurs de recherche. Il s’agit de mettre à la disposition de ces moteurs de recherche les informations les plus souvent sollicitées par les lecteurs lors de leurs requêtes.
Principe : Lorsqu’un nouveau document vient s’ajouter au sein de la bibliothèque, on lui attribue tout d’abord un numéro d’identification (unique pour chaque document) puis on crée son index. Les personnes chargées de la création des index de documents sont appelées des "indexeurs". C’est eux qui vont saisir, par l’intermédiaire d’un logiciel d’indexation, les informations concernant le document.
En conséquence, chaque document est répertorié par un identificateur et une liste d’informations (méta-données).
Ces informations comportent en général :
Remarque : On peut distinguer deux types d’information dans les méta — données :
Les méta- données sont donc des informations structurées, qui ont pour rôle de décrire formellement le document au sein duquel elles se trouvent. Généralement cachées au simple lecteur, c’est elles qui sont utilisées par les moteurs de recherches. C’est sur les méta — données qu’ils vont effectuer leurs requêtes.
Les méta — données s’expriment toujours à travers un langage d’indexation [FOUREL96]. Les méta-données sont toujours décrites avec une structure de lignes particulière.
Par exemple une des structures couramment employée est la suivante (pour DOC’INSA notamment) :
<META name="xxxx" scheme = "yyyy" content="zzzz">
avec les paramètres du tableau ci-dessous. (cf figure 2)
|
Name |
Scheme |
Content |
Commentaire |
|
DC.creator. personnalname |
(LANG=fr) Auteur de la thèse |
Nom, prénom |
|
|
DC.creator.email |
Mail de l'auteur |
||
|
DC.creator.origin |
Origine de l'auteur |
Laboratoire, Université |
|
|
DC.contributor |
Nom du Directeur de thèse |
||
|
DC.title.main |
(LANG=fr) Titre principal de la thèse |
||
|
DC.title |
(LANG=fr) Titre secondaire de la thèse |
||
|
DC.type |
Thesis |
Type de publication |
|
|
DC.subject.keywords |
(LANG=fr) Mots clés |
||
|
DC.description |
(LANG=fr) Résumé de la thèse |
||
|
DC.identifier |
ISAL |
numéro ISAL de la thèse |
|
|
DC.format |
ADOBE ACROBAT PDF |
||
|
DC.Language |
Fre |
Langue de la thèse (code sur 3 caractères) |
|
|
DC.date.creation |
Date de soutenance YYYY-MM-JJ |
||
|
DC.identifier |
URL |
http://www.csidoc.insa-lyon.fr/ these/année/nom_docteur |
|
|
DC.Publisher |
CITHER - Doc'INSA - INSA de Lyon |
Nom du projet de mise à disposition |
|
|
DC.Publisher |
Doc'INSA — INSA de Lyon |
Nom et adresse de l'organisme développant le projet CITHER |
Figure 2 : Tableau de quelques paramètres (exemple pour DOC’INSA)
Remarque :A travers ce tableau (cf .figure 2), on note l’importance de la langue dans laquelle ont été saisies les informations. Il est toujours précisé en quelle langue le document, le résumé ou les mots —clé sont rédigés. Afin de couvrir un plus large éventail, les informations sont souvent traduites en plusieurs langues : les mêmes informations sont répétées mais dans des langues différentes. Pour cela, le paramètre LANG permet de préciser la langue dans laquelle est enregistrée l’information. Exemple : (LANG = en) pour English, (LANG = fre) pour French.
On retrouvera aussi souvent dans les méta — données d’un document son code de classification, car les personnes habituées à l’utilisation des codes de classification (comme les bibliothécaires) effectueront souvent des recherches par code.
Les méta — données doivent toujours être structurées selon un modèle bien précis de manière à pouvoir être utilisées par le plus grand nombre de moteurs de recherche. Le but des méta — données étant de rendre les documents indexés les plus accessibles possible.
L’indexation est donc une nécessité pour les bibliothèques virtuelles si on veut pouvoir effectuer des recherches via un moteur de recherche.
Cependant, toutes les bibliothèques mettent aussi parallèlement à la disposition de leurs lecteurs un catalogue pour faciliter leurs recherches.
Ce catalogue est généralement mis à la disposition des utilisateurs de la bibliothèque virtuelle sous format électronique. Tous les documents y sont référencés (avec une brève description) avec leur adresse URL (pont d’embarquement) permettant d’y accéder directement. Il est aussi souvent possible de faire des recherches directement sur le catalogue. Ces recherches sont évidemment moins " poussées " car les informations contenues dans le catalogue sont plus synthétiques.
Une fois les documents correctement indexés, il sera facile d’effectuer des recherches au sein de la bibliothèque virtuelle.
La phase de recherche d’information [FOUREL96] est la phase d’interaction entre le système de recherche d’informations et l’utilisateur. Ce dernier exprime son besoin d’information via un langage de requête (langue naturelle, ensemble de mots — clés,…) que le système de recherche va se charger de traduire. Cette traduction a pour but de comprendre les besoins de l’utilisateur et de les exprimer dans un formalisme similaire à celui utilisé pour la création des méta — données dans la phase d’indexation.
Une fois la requête traduite, le système de recherche, calculera la correspondance entre la requête de l’utilisateur et chaque index de document.
Le calcul de cette correspondance dépend du type de recherche utilisé.
On recense essentiellement deux types de recherches de documents :
La recherche en texte intégral [BANMIT95] est la recherche la plus approfondie, mais son inconvénient est sa lenteur d’exécution. La recherche par mots clés est moins approfondie mais a de très bonnes performances. En général, c’est la recherche par mots clés qui est utilisée dans les bibliothèques virtuelles.
Un inconvénient est toutefois commun à ces deux types de recherches : les documents trouvés ne correspondent pas toujours aux attentes de l’utilisateur. De plus, le nombre de documents récupérés est souvent si élevé qu’il n’est pas évident de faire le "tri " soi-même sans perdre énormément de temps.
Le problème avec ce type de recherches, c’est qu’elles ne tiennent pas compte du fait que la plupart des mots possèdent de nombreux sens et qu’un mot peut avoir de nombreux synonymes.
Si on veut proposer une recherche efficace, il faut être capable de cerner au mieux les attentes de l’utilisateur. C’est ainsi que l’on voit apparaître de nouveaux types de recherches dites "recherches assistées ", où l’utilisateur va être guidé tout au long de ses recherches.
Le principe de ces recherches est le suivant : l’utilisateur va émettre une requête, le moteur de recherche va analyser du mieux possible la sémantique de la requête. Si plusieurs interprétations peuvent être obtenues, il va les proposer à l’utilisateur afin que celui — ci valide celles qui l’intéressent. Ensuite le moteur de recherche va proposer des requêtes qui lui semblent similaires (grâce à l’existence de synonymes). L’utilisateur pourra là aussi préciser celles qui lui conviennent. Enfin, la recherche sera lancée, elle sera ainsi plus ciblée et les résultats seront moins nombreux et satisferont mieux l’utilisateur.
On juge la qualité d’un moteur de recherche selon son aptitude à donner tous les documents jugés pertinents par l’utilisateur.
Malheureusement, les moteurs de recherches actuels ne prennent pas suffisamment en compte l’aspect sémantique, ce qui rend souvent les recherches fastidieuses.
Un autre point important concernant les moteurs de recherche concerne leur interface utilisateur.
La plupart des moteurs de recherche [VEERNAV95] ont une interface très pauvre et peu intuitive. De plus, la plupart du temps les requêtes doivent être énoncées selon un format particulier (utilisation d’opérateurs logiques : exemple l’opérateur " ou " peut s’exprimer " or " ou " + "…). Il n’y a pas réellement de standard, ce qui n’en facilite pas l’apprentissage et qui plus est l’utilisation.
Il ne faut pas oublier, que les personnes susceptibles d’utiliser les services de ces moteurs de recherches ne sont pas familiarisées avec le monde informatique mais avec celui des bibliothèques. Il faut donc leur permettre de retrouver des points de repères, des mécanismes similaires à ceux présents dans les terminaux de recherches d’une bibliothèque classique.
Un moteur de recherche doit posséder une ergonomie attrayante, claire et facile à utiliser. Il ne faut pas que cela soit un véritable " parcours du combattant " pour émettre une requête. Tout utilisateur doit pouvoir rechercher facilement des documents.
L’interface utilisateur d’un moteur de recherche doit pouvoir aider l’utilisateur, lui poser des questions sur la recherche qu’il désire faire, lui donner des pistes de recherches pour élargir sa recherche si celle-ci ne s’est pas avérer fructueuse.
Elle doit d’autre part être facile d’utilisation, les glisser — déplacer doivent être largement employés.
Enfin un dernier point primordial concernant l’interface utilisateur est la visualisation des résultats d’une recherche. On doit obtenir une visualisation claire des documents obtenus avec suffisamment d’informations sur chacun d’entre eux pour que l’utilisateur puisse facilement faire un premier tri (à l’aide de la souris par exemple).
En respectant l’ensemble de ces consignes, la recherche de documents au sein d’une bibliothèque virtuelle peut devenir très attrayante et performante. Il faut à présent étudier comment mettre en place de tels systèmes pour répondre aux attentes des utilisateurs, quelles architectures doit-on adopter ?
Les bibliothèques virtuelles peuvent reposer sur des architectures techniques basées sur des technologies différentes. Ces architectures se différentient par leur coût et leur difficulté de mise en place, leur performance, leur évolutivité ainsi que leurs solutions pour traiter le problème des accès distants. Il sera donc présenté dans cette partie différentes technologies pouvant répondre aux problèmes liés aux bibliothèques virtuelles. Puis certains composants particuliers, pouvant être implémentés sur ces différentes architectures, seront exposés. Ensuite, cette partie présentera quelques systèmes de bibliothèques virtuelles existantes et se terminera en essayant de répondre à la question " Comment évaluer les solutions adoptées pour l’architecture d’une bibliothèque virtuelle ? ".
Les architectures des bibliothèques virtuelles reposent en général sur plusieurs composants communiquant entre eux. De par ce fait, le problème majeur rencontré est le problème de l’interopérabilité des systèmes [PAEPCHANG98]. Cette conception basée sur des composants indépendants pouvant se situer sur des sites différents, n’est pas seulement due à des raisons techniques et de performance. Elle est aussi liée au fait que le stockage des informations et les traitements associés sont assurés par des organisations indépendantes. Ce problème d’interopérabilité se retrouve aussi au niveau des accès distants puisque les clients peuvent fonctionner sur plusieurs systèmes hétérogènes.
Le problème de l’interopérabilité touche de nombreux domaines :
Pour répondre à ce problème, différentes solutions sont envisageables :
Ces protocoles standards sont une bonne solution, mais il est parfois difficile d’y agréer car cela peu exiger des infrastructures coûteuses et une réalisation complexe du fait que les protocoles ne sont pas spécifiques aux problèmes des bibliothèques virtuelles.
L’approche par les familles de standards est plus souple car elle permet plus de choix, mais elle présente un problème lié à l’absence de standards dans certains domaines.
Les passerelles et les proxys permettent la transparence entre le client et le système de la bibliothèque virtuelle. En général, cette solution est aussi basée sur les méta-données afin que les proxys puissent connaître le plan de répartition des informations et des traitements.
Le but est de décrire toutes les demandes et tous les services pour les échanges entre chaque composant. Plusieurs technologies sont basées sur ce système comme notamment ACL (Agent Community Langage) ou KIF (Knowledge Interface Format) qui s’appuient sur une connaissance partagée entre plusieurs agents logiciels. Il est aussi possible de mettre en place une description sémantique des fonctionnalités des composants grâce à SETL ou PAISLey.
Les fonctionnalités mobiles sont des fonctionnalités qui sont téléchargées pour être exécutées dans un même environnement (Ex : Applets Java). Ensuite ces fonctionnalités communiquent avec des composants restant sur le système grâce à des appels de procédures distantes qui sont basés en général sur les technologies CORBA et DCOM.
On peut s’apercevoir que cette dernière solution est aussi basée sur des standards comme CORBA. En fait, ces différentes solutions ne doivent pas être vues comme indépendantes mais doivent être utilisées conjointement afin d’élaborer une architecture technique performante.
4.1.2 L’apport de CORBA au problème des bibliothèques virtuelles
Les spécifications CORBA de l’OMG (Object Management Group) permettent de mettre en place des architectures basées sur des objets indépendants qui communiquent via un ORB (Object Request Broker). Les différents composants de la bibliothèque virtuelle sont composés de un ou de plusieurs objets CORBA [PAEPCOUS96], [CHANGPAEP97]. De cette manière, la répartition physique des composants n’est plus un problème et en plus la sécurité des données est assurée du fait de leur encapsulation à l’intérieur des objets.
CORBA est aussi une bonne solution pour les échanges entre plusieurs systèmes de bibliothèques virtuelles basés sur cette technologie. Car même si CORBA n’est qu’un ensemble de spécifications implémentées plus ou moins dans chaque ORB des éditeurs, il est possible d’interconnecter ces ORB grâce au protocole IIOP (Internet Inter ORB Protocol).
En ce qui concerne l’évolutivité, ce système est tout à fait adapté. En effet, chaque objet est spécialisé dans une tâche qui peut être le contrôle des accès à la bibliothèque virtuelle, la gestion des échanges avec les clients, le recherche ou le stockage des données, etc. Il est donc facile de rajouter un objet afin qu’il prenne en charge de nouvelles fonctionnalités. De plus, les objets pouvant être répartis sur plusieurs serveurs différents, les traitements peuvent être coopératifs et assurer ainsi de bons temps de réponses aux requêtes des clients.
La répartition en couches des fonctionnalités est une solution bien connue et elle est bien entendu applicable aux bibliothèques virtuelles. Chacune des couches est spécialisée dans une catégorie de traitements propres aux bibliothèques virtuelles [SHENMUK95], [NURFURU95]. On peut donc ainsi retrouver les différentes couches suivantes :
Cette couche est l’interface entre le client et le système et c’est elle qui se charge de la gestion des accès. Elle contient l’ensemble des interfaces graphiques qui peuvent être différentes selon le client ou selon l’application et la source d’information à laquelle l’utilisateur accède (utilisation de HTML et/ou des applets JAVA).
Cette couche a pour but de lever le problème de l’interopérabilité. Elle sert de traducteur entre la couche d’interface haute et la couche dépôt de données. Cette couche permet de masquer l’aspect distribué des données en les faisant percevoir pour la couche d’interface haute comme un unique espace de données virtuelle. Les fonctions offertes par cette couche sont celles liées à la consultation, à la recherche et à l’administration des données (ajout, modification, suppression de données).
Les données sont contenues dans cette couche et sont accédées par la couche d’interopérabilité grâce à une API proposant les services suivants :
Le schéma suivant montre comment les différentes couches peuvent être implémentées :
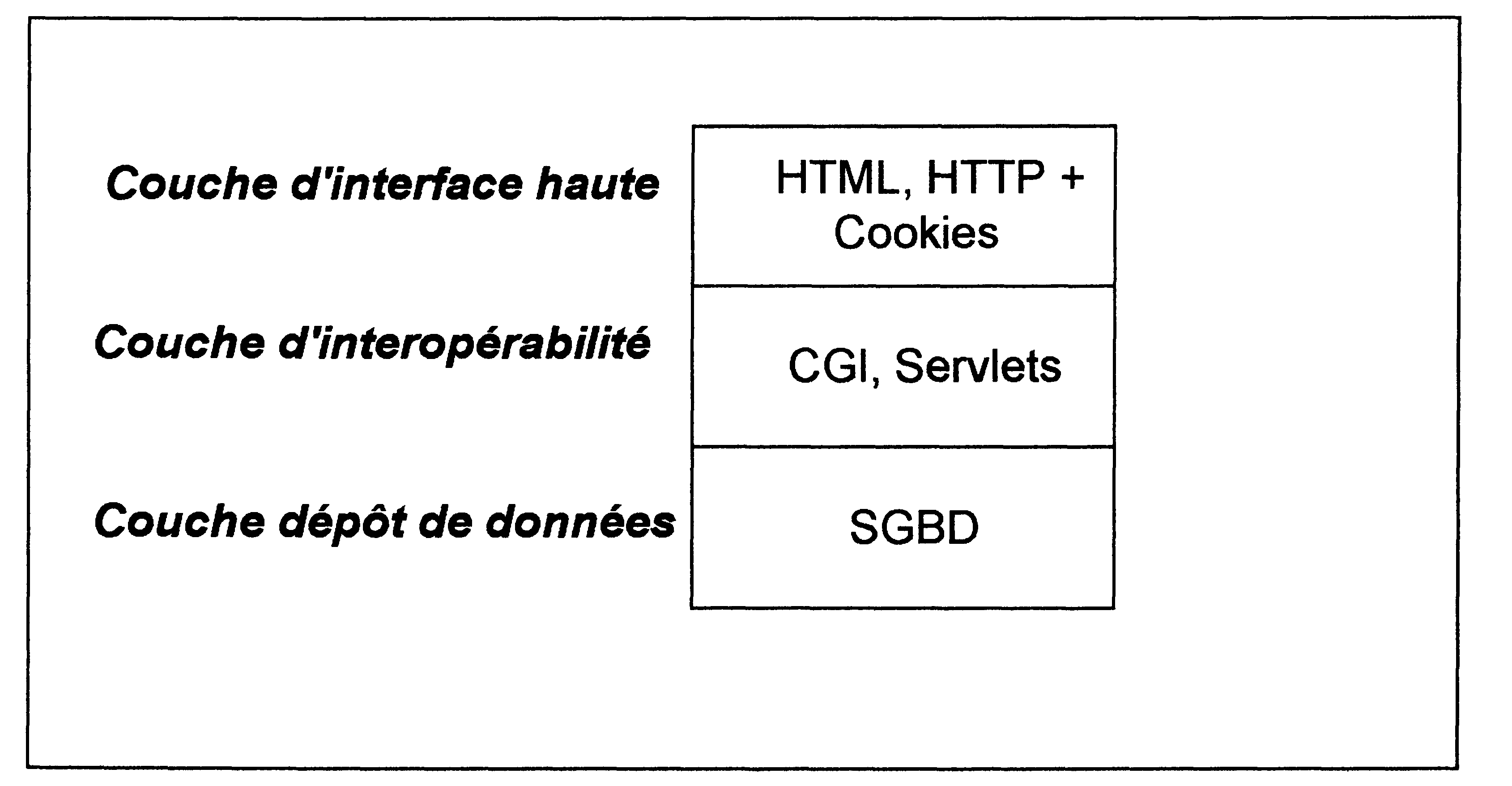
Figure 3 : Implémentation des couches
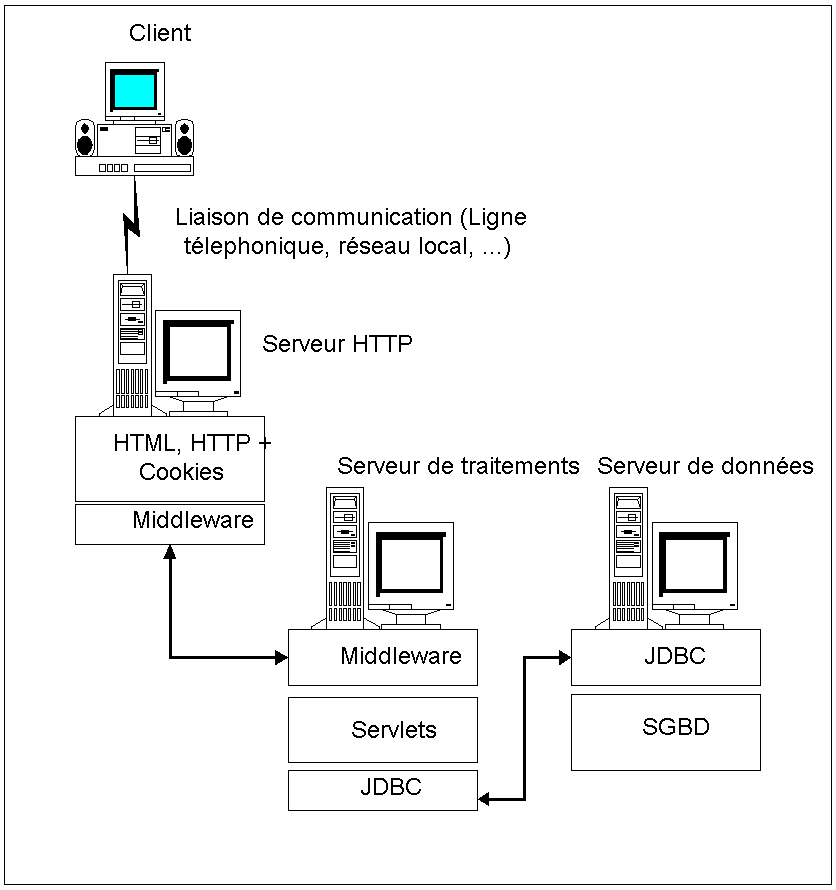
Chacune de ces couches peut être située sur une ou plusieurs machines. Sur plusieurs machines, il se pose alors le problème de la communication entre les couches qui peut être résolu par l’utilisation de standards (JDBC) ou de logiciels de middleware (Voir figure ci-dessous).
Figure 4 : Exemple d'implémentation physique des couches
Les systèmes de gestion de documents sont des logiciels dont le fonctionnement est semblable aux systèmes de gestion des fichiers des systèmes d’exploitation [TOCHT97]. Leurs fonctionnalités sont simplement étendues afin qu’ils puissent gérer des documents de types très différents. Les documents sont organisés de façon hiérarchique à l’intérieur de collections. Une collection peut être composée de documents ou d’autres collections. Au niveau de chacune des collections, il existe une gestion des droits d’accès. Chaque collection contient des documents de différents types qui peuvent être des catalogues de données, des documents numériques, des ressources Internet (URL) ou des aides en ligne. En plus de ces collections attachées à ce type de documents, il existe deux collections particulières qui servent à la communication dans le système. Ces collections contiennent les services et le workspace (le workspace est un espace de travail où les bibliothécaires peuvent stocker des documents privés) (Cf. Figure 5).
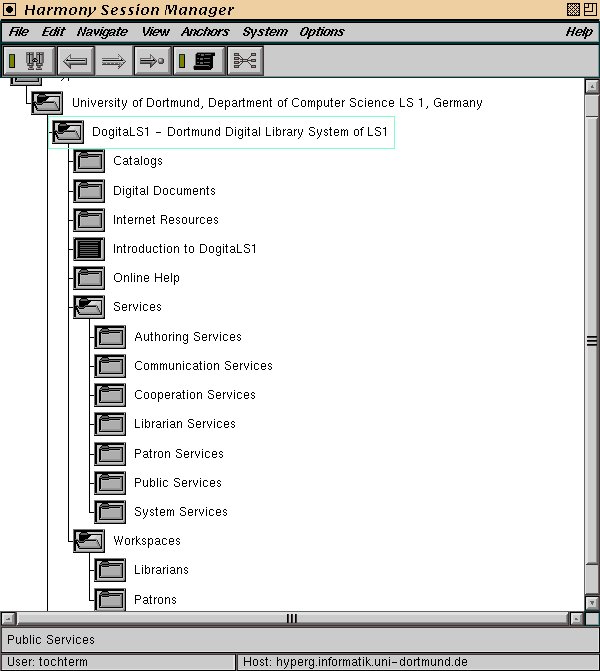
Figure 5: Répartition hiérarchique des collections.
Le protocole Z39.50 est un protocole standard ISO (ISO 23950) souvent utilisé dans les architectures des bibliothèques virtuelles pour cataloguer et indexer les documents afin de permettre des recherches efficaces [MOEN98], [NEBFULL97]. Cette recherche peut être distribuée et peut être basée sur plusieurs moteurs de recherche.
En fait ce protocole sert de passerelle entre les clients et le système de recherche de la bibliothèque virtuelle (Cf. Figure 6). Il masque entièrement la structure des données en offrant un ensemble d’attributs et de services. Ces attributs et ces services sont expliqués dynamiquement par le serveur au client. Le client interroge ainsi le serveur grâce aux services et sur les attributs offerts par le protocole. Une fois que le protocole a reçu les requêtes portant sur ses attributs, il va interroger les différents moteurs de recherche grâce à une API spécifique.
Ce mécanisme permet donc de mettre en place des fonctions de recherche homogènes quelle que soit la technique de recherche utilisée ensuite par le système de la bibliothèque virtuelle. De plus, ce protocole permet des recherches plus efficaces car il est capable, par exemple en interrogeant correctement les différents moteurs de recherche, de retrouver un même document sous plusieurs formats différents.
En ce qui concerne l’accès aux serveurs Z39.50 par les clients, celui-ci peut se faire de différentes façons. Soit le client possède le protocole et il peut directement se connecter au serveur, soit le client se connecte tout d’abord à un serveur HTTP qui lui possède le protocole et qui va ensuite se connecter au serveur Z39.50.
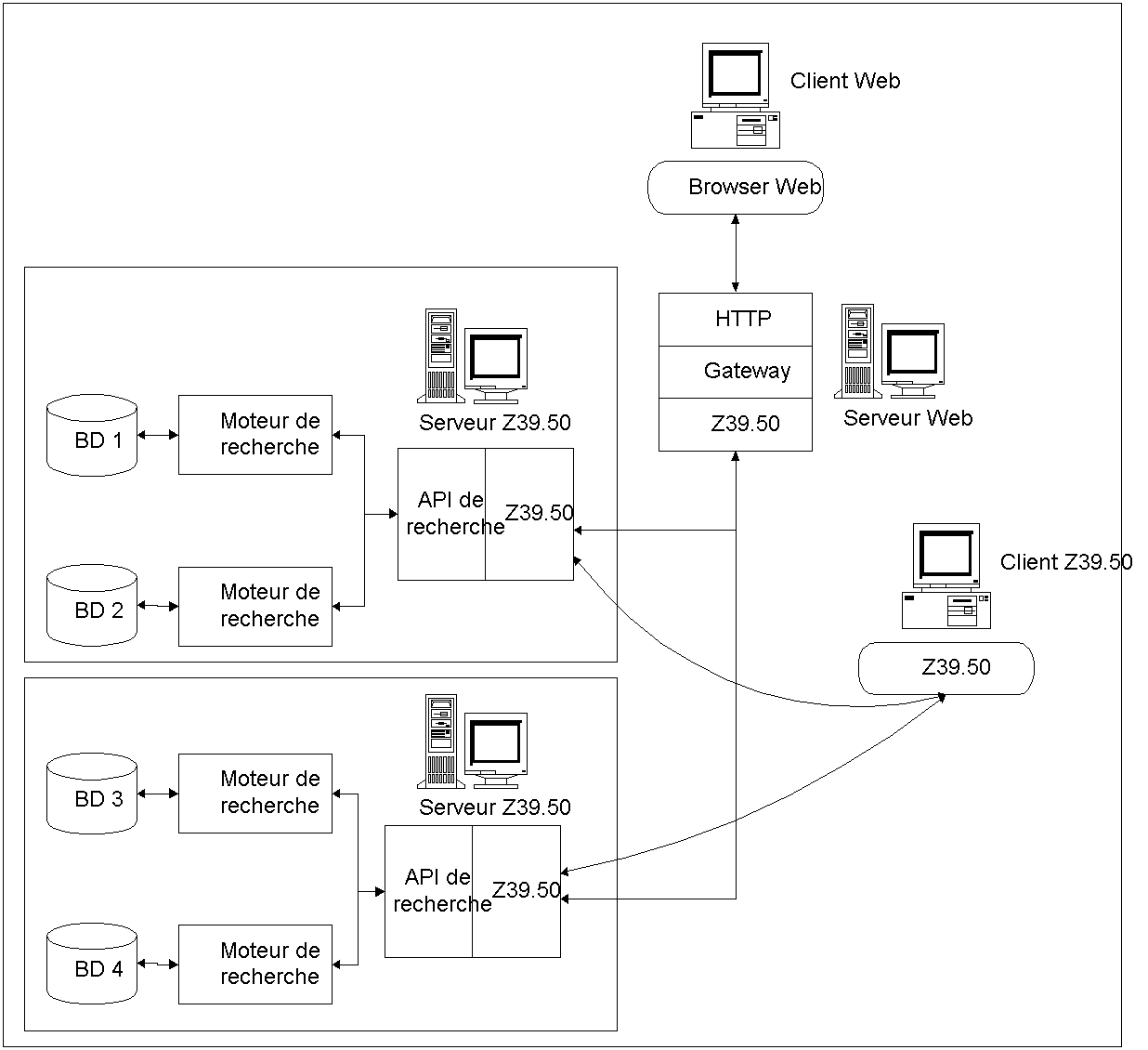
Figure 6: Exemple d'architecture Z39.50
Les proxys sont des composants logiciels constituant un point d’entrée au système de la bibliothèque virtuelle [CHANGPAEP97]. Ils peuvent être implémentés sur une machine dédiée ou non. Ils sont en général basés sur les objets CORBA et communiquent avec les autres composants du système via un ORB, un protocole (HTTP, Z39.50) ou un InfoBus. Les proxys ont pour rôles principaux ceux de passerelle entre le client et le système de la bibliothèque virtuelle ainsi que celui de mémoire cache.
Le principe de fonctionnement des proxys est le suivant. Le client se connecte tout d’abord au proxy et lors de toute recherche de document, le proxy va d’abord regarder s’il ne possède pas dans sa mémoire le résultat de la requête envoyée. Si cela ne figure pas dans sa mémoire, il va alors interroger les différents moteurs de recherche du système, stocker le résultat dans sa mémoire et le renvoyer au client.
Les proxys améliorent ainsi les performances du système et répondent au problème de l’interopérabilité entre le client et le système de la bibliothèque virtuelle de part le fait qu’ils traduisent les requêtes du client. Les proxys basés sur les objets CORBA permettent une grande évolutivité car il est alors facile de rajouter un nouveau proxy rattaché à une nouvelle source de données. Cet ajout est d’autant plus facile qu’il existe des logiciels permettant la génération automatique de proxys logiciels.
Les méta-données sont aussi un point essentiel des proxys. En effet, chaque proxy possède sa propre base de données stockant des résultats de requêtes préalables et sa propre base de méta-données. Cette base de méta-données lui fournit ainsi un plan de la répartition des données dans le système de la bibliothèque virtuelle et il sait donc à quel composant il doit s’adresser pour rechercher ou accéder à tel ou tel document.
Le dialogue entre les proxys et le reste des composants doit être très efficace. C’est pourquoi l’utilisation d’Infobus est préconisée. L’InfoBus est un bus logiciel qui permet la communication entre les différents composants du système [QUATERREPORT98]. Il possède un rôle de traducteur par le fait qu’il est une structure de données intermédiaire que tous les composants respectent pour communiquer entre eux. L’InfoBus ne se contente pas de traduire en recopiant des attributs sources dans des attributs destination, il effectue aussi une conversion des valeurs (ex : s’il existe 4 attributs sources et 1 attribut destination pour le nom des auteurs du document, l’InfoBus peut recopier les 4 attributs dans l’unique attribut destination en les séparant par des virgules). Les InfoBus fonctionnent sous le principe de producteur consommateur. Un composant consommateur s’abonne à un type d’information. Lorsqu’un producteur fournit le type d’information, le consommateur est alors averti et ce dernier peut recopier l’information. Bien entendu, plusieurs composants peuvent s’abonner au même type d’information et plusieurs producteurs peuvent mettre à disposition, en même temps, le même type d’information. Les InfoBus permettent aussi une bonne évolution car ils constituent un " framework " où chaque composant du système de la bibliothèque virtuelle est connecté et reconnu dynamiquement.
Certaines bibliothèques virtuelles demandent une cotisation, annuelle ou par document, de la part de leur lecteur. Il est donc nécessaire dans ces cas de mettre en place un mécanisme de paiement électronique. Il existe différents mécanismes de payement électronique et différents standards. L’ensemble de ces mécanismes et de ces standards ne sera pas expliqué, mais il sera présenté à la place le système InterPay de la bibliothèque virtuelle de l’université de Stanford qui est un système répondant à un nombre important d’exigences en matière de paiement électronique pour les bibliothèques virtuelles [PAEPCOUS96].
Le système Interpay est un système composé de 3 couches qui sont les suivantes (Cf. Figure 7) :
L’interface contenant l’ensemble des services de payement électronique offerts aux clients est située dans cette couche.
Cette couche contrôle et fait respecter les règles de payement. Ces règles sont implémentées dans des " payment agents " et dans des " collection agents ". Les " payment agents " sont liés aux clients tandis que les " collection agents " sont liés à la bibliothèque virtuelle. Les " payment agents " permettent aux clients de configurer leur méthode de payement (exemple de règle pouvant se trouver dans un " payment agent " : payer une somme de 1$ ou moins sans avertir le client, mais avertir le client lorsque le total dépasse 30$). Les " collection agents " possèdent quant à eux des règles concernant les payements différés pour les clients de confiance ou sur la limitation d’utiliser un certain mécanisme de payement (pour de petites transactions par exemple).
C’est la couche qui contient les différents mécanismes de payement. Elle est composée de deux types de composants qui sont les " payment capabilities ", qui permettent aux clients d’interagir avec un mécanisme de payement, et les " collection capabilities ", qui sont l’implémentation des mécanismes de payement.
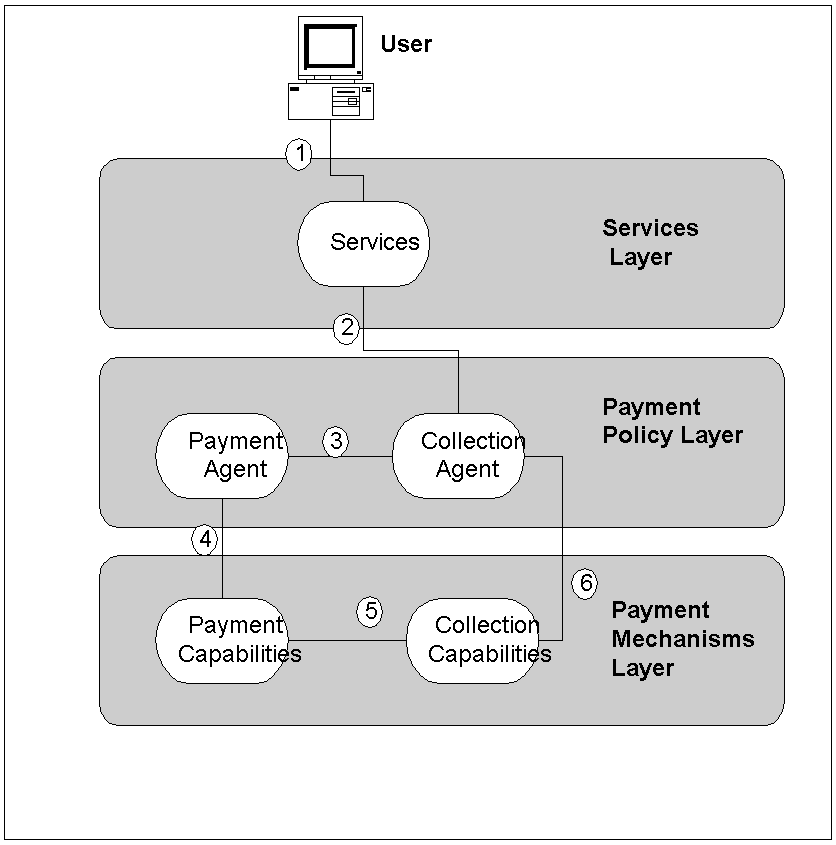
Figure 7 : Interactions entre les différents composants de système Interpay
Légende
1- Configuration de la session et création de la requête (négociation des mécanismes de payement utilisé)
2- Engagement d’une somme
3- Envoie d’une facture
4- Validation de la facture et confirmation du mécanisme de payement utilisé
5- Lancement du transfert d’argent
6- Vérification du payement et fin de la transaction.
Ce système est aussi capable d’effectuer des payements tripartis (Cf. Figure 8). C’est à dire qu’il est possible d’interconnecter les systèmes Interpay de deux bibliothèques virtuelles. Le client pourra ainsi acheter un document que la bibliothèque virtuelle, à laquelle il est connecté, ne possède pas. Cette dernière l’achetant à une autre bibliothèque virtuelle ou à un organisme particulier. Le fonctionnement reste identique au cas précédemment expliqué ci-dessus, sauf que dans ce cas la bibliothèque virtuelle porte à la fois le rôle de client et de fournisseur.
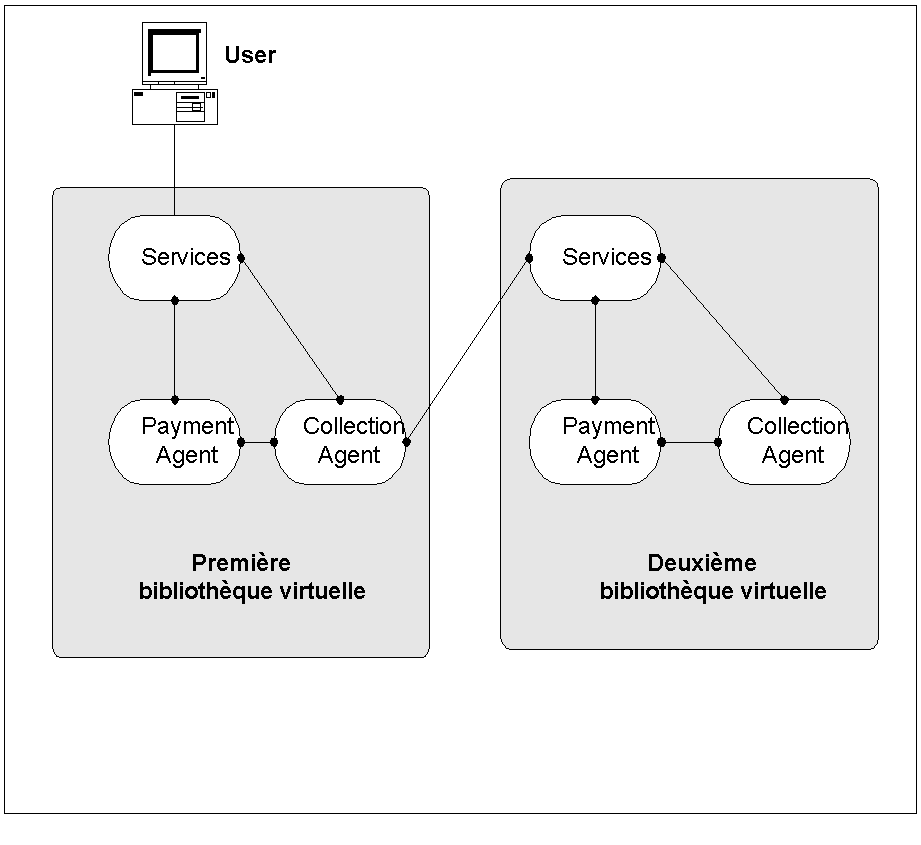
Figure 8 : Payement tri-parti
Cette étude de cas a pour but de montrer les infrastructures mises en place dans les bibliothèques virtuelles, ainsi que l’application, dans des cas réels, des technologies précédemment décrites.
La Bibliothèque Nationale de France a mis à disposition du public une salle audiovisuelle [MONY97]. Dans cette salle, il est possible d’y consulter 120 H de vidéo (documentaires), 250 H de son (interview et musique) et 50 000 photos à partir de 45 stations. Pour offrir ces services multimédias l’architecture informatique suivante a été mise en place.
Le studio de digitalisation est constitué d’un robot de digitalisation (pour les documents papier) et d’un PC équipé d’un logiciel fournit par la société CCETT (pour les sons). La digitalisation des photos est quant à elle confiée à une société extérieure. Les formats de compressions utilisés sont MPEG2 pour les vidéos, Audio MPEG Layer 2 pour les sons et JPEG pour les photos (Cf. Figure 9).
Le stockage des données est assuré par deux serveurs Alex. Le premier serveur se charge de stocker la vidéo et l’audio et possède une capacité de 648 Go. Ce serveur est en fait constitué de plusieurs machines en cluster. Pour ceci, il utilise une architecture de traitements coopératifs sur plusieurs machines dit MPP (Massively Parallele Processing). En ce qui concerne les photos, celles-ci sont stockées sur le deuxième serveur Alex qui possède une capacité de stockage de 164 GO. Elles sont stockées sous 3 résolutions différentes (128x192, 512x768, 1024x1536) selon la qualité désirée. Le transfert des photos aux stations multimédia est effectué par l’intermédiaire d’un PC Pentium qui se charge de trouver la photo dans la résolution voulue. En plus de ces données, les utilisateurs peuvent accéder à 300 CD-ROMs (gérés par un juke-box) via 8 stations de travail dédiées. Pour la vidéo et l’audio, il existe, en complément du serveur, 2 robots GRAU (le premier robot stockant 2 880 cassettes vidéo S-VHS et le second stockant 11 250 disques compacts).
Le réseau local chargé du transfert de ces données est un réseau ATM (Asynchronous Transfer Mode) avec 2 commutateurs backbone COLLAGE 740 de MADGE NETWORK. Chaque étage de la bibliothèque possède un commutateur ATM à 25 Mb/s tandis qu’entre ces commutateurs et les deux commutateurs centraux le taux de transfert est de 155 Mb/s.
Les stations de travail sont quant à elles de 4 types différents :
Le nombre de station de travail est de 45 et il est prévu de l’étendre jusqu’à 145. Chaque station fonctionne sous Windows 95 (une migration vers Windows NT4 est prévue) et est équipée d’un processeur Pentium 133 Mhz avec 32 MO de RAM et 1.2 Go de disque dur. Ces stations sont aussi équipées de cartes vidéo de décompression MPEG2 (VIDEOPLEX de OPTIBASE), de cartes son (SoundBlaster 64 de CREATIVE LABS) et de cartes réseau ATM 25 MAGGE.
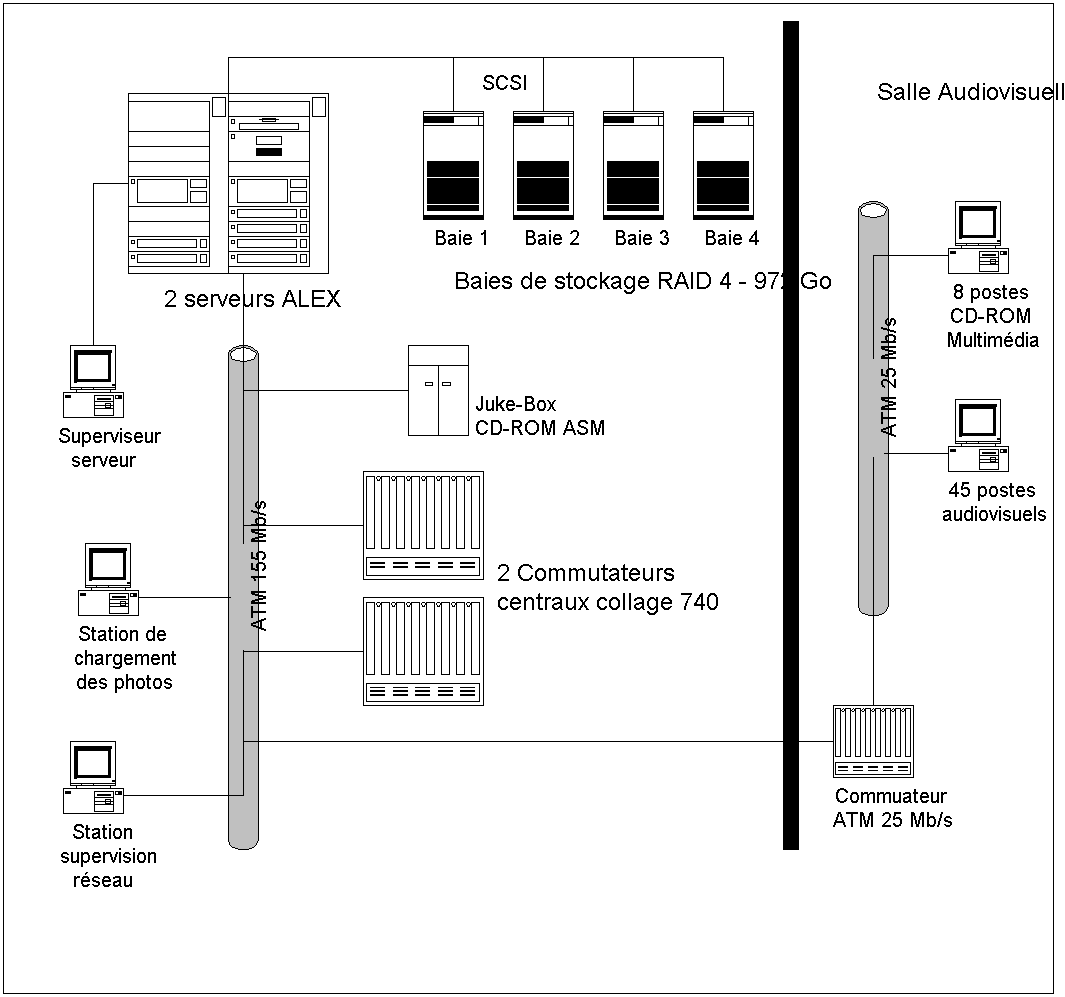
Figure 9 : Architecture informatique liée à la salle audiovisuelle de la Bibliothèque Nationale de France
La bibliothèque virtuelle de l’université du Kansas met à disposition de ses usagers un certain nombre de documents vidéos [GAUCHAUST94]. Cette bibliothèque virtuelle spécialisée dans les documents vidéos est accessible par Internet. Ces documents sont essentiellement des documentaires sur la nature provenant du WNET et des reportages produit par CNN.
Le système de cette bibliothèque virtuelle a été conçu par le Digital System Research Center à Palo Alto et a pour nom DVLS (Digital Video Library System). Ce système est un système en couches hiérarchiques qui propose des fonctions d’indexation et de catalogage des documents. Il est basé sur des modules ayant les mêmes particularités et dont le nombre varie selon les volumes de données à stocker et selon le nombre d’accès utilisateurs simultanés.
Un module est capable de supporter 20 clients simultanément et peut délivrer jusqu’à 500 minutes de vidéo par heure. Il est basé sur un serveur Digital DecStation 3000 Alpha Station équipé de trois bus externes Fast SCSI-2 et de deux cartes ATM à 155 Mb/s. Le stockage des données est assuré par 3 systèmes de disque dur externes (deux avec un taux de transmission à 5.5 Mb/s et un à 2.7 Mb/s) contenant 7 disques de 2.1 Go (soit 14.7 Go au total). Les vidéos sont stockées sous le format MPEG et il faut deux modules pour en stocker environ 100 heures.
Selon les accès, il sera utilisé un taux de transfert et un taux de compression des vidéos différent.
|
Accès local |
Utilisateurs proches |
Utilisateurs distants |
|
|
Taux de transfert |
ATM à 155 Mb/s |
Réseau radio à 1.5 Mb/s |
Accès Internet par modem à 14.4 Kb/s |
|
Taux de compression |
Pas de compression supplémentaire par rapport à la compression de stockage. La taille des vidéos correspond à celle stockée. |
Taille de l’image réduite à 320 x 240 pixels et compression MPEG plus importante (taux à 23 :1). |
Taille de l’image réduite à 160 x 120 pixels et compression MPEG plus importante (taux de 30 :1). |
Remarque : il est aussi utilisé un protocole différent selon le type d’accès.
Le système de test mis en place pour l’instant est basé sur 2 modules. Les résultats ont montré qu’il est très performant jusqu’à 10 utilisateurs simultanés et qu’il se dégrade sensiblement entre 20 et 30 utilisateurs simultanés.
Le système que propose Doc Insa, est un système permettant l’accès à des banques de données achetées (stockées sur CD-ROMs) et à un certain nombre de thèses en texte intégral.
La solution adoptée pour la gestion des thèses est une solution de type système de gestion de documents. Elle est basée sur un serveur UNIX, possédant 18 Go en capacité de stockage et 256 Mo de Ram, et sur le progiciel Doris Loris de la société Ever. Ce progiciel offre les fonctions de catalogage et d’indexation des documents. Les fonctions propres à Doris Loris ne sont consultables que par les membres du personnel via un terminal (ou un émulateur) VT320. Toutefois, il est offert la possibilité aux usagers de consulter le catalogue des documents via une interface HTML.
La recherche des données est réalisée par un moteur de recherche Alta Vista qui se base sur des méta-données présentes dans la page d’embarquement de chaque thèse. Chaque thèse est un document au format PDF qui est pointé par une page de présentation en HTML dit page d’embarquement. Cette page présente un certain nombre d’informations sur le document comme le nom de l’auteur, le résumé, le plan, etc.
En ce qui concerne les banques de données, celles-ci sont prises en charge par un réseau de CD-ROM contenant 15 CD-ROMs qui est supporté par deux serveurs NT.
L’accès par les utilisateurs au système (dont le moteur de recherche, le catalogue des thèses et les banques de données) se fait par réseau Intranet et est assuré par un serveur Web Apache.
L’université de Stanford a mis en place une bibliothèque virtuelle fondée sur une architecture innovante, basée sur les nouvelles technologies du moment. Cette architecture repose sur des objets distribués CORBA et sur l’utilisation d’un InfoBus [PAEPCOUS96]. Chaque composant, spécialisé dans une fonction (contrôle d’accès, recherche d’informations, stockage, …), est constitué d’un ensemble d’objets CORBA et peut communiquer avec les autres composants via l’Infobus. En ce qui concerne les accès distants par Internet (HTTP), ceux-ci sont pris en charge par des proxys logiciels. Cette solution permet donc de résoudre le problème de l’interopérabilité entre le client et le système, permet de bonnes performances et une bonne évolutivité (pour chaque nouveau service offert par la bibliothèque virtuelle, celui-ci est réalisé par un ensemble d’objets CORBA et est lié à un nouveau proxy logiciel). Ces avantages sont aussi renforcés par l’utilisation du protocole Z39.50 entre les proxys et les moteurs de recherche.
Cette architecture s’articule autour des produits et des solutions suivantes :
Les architectures sont difficiles à comparer entre elles du fait que chacune correspond à des besoins et à des exigences différentes selon les systèmes de bibliothèque virtuelle. De plus, les solutions techniques, sur lesquelles elles s’appuient, sont elles aussi difficiles à comparer et ne sont pas, en général, compatibles. Par conséquent le choix des technologies employées pour réaliser l’architecture est très important.
Toutefois, il est possible d’évaluer les différentes architectures et ainsi trouver celle qui correspond le mieux aux besoins et aux exigences. Cette évaluation est basée sur les 6 critères suivants :
A leur apparition, les bibliothèques numériques ont posé des problèmes juridiques quant aux droits d’auteur. En effet l’utilisation électronique des œuvres étant nouvelle, elle n’avait pas été prévue initialement dans l’élaboration des lois sur la protection des droits d’auteur. Il existe actuellement un traité international qui tient compte de ces nouvelles données. Cependant cela apporte des contraintes trop grande selon l’ECUP (European Copyright User Platform) qui propose de nouvelles solutions
L’Organisation Mondiale de la Propriété Intellectuelle (OMPI) est une organisation intergouvernementale dont le siège est à Genève, en Suisse. Elle fait partie des institutions spécialisées du système des Nations Unies. Elle est chargée de promouvoir la protection de la propriété intellectuelle à travers le monde par la coopération des Etats et d’assurer l’administration de divers traités multilatéraux touchant aux aspects juridiques et administratifs.
L’OMPI a conclu un deuxième traité sur le droit d’auteur à Genève le 20 décembre 1996. Ce traité définit les droits reconnus à l’auteur en particulier le droit de communication au public. Il s’agit du droit d’autoriser toute communication au public, par fil ou sans fil, y compris " la mise à disposition du public [d’] œuvres de manière que chacun puisse y avoir accès de l’endroit et au moment qu’il choisit de manière individualisée ". Cela couvre la communication interactive, à la demande, par le réseau Internet. Donc selon cette phrase, les bibliothèques numériques doivent avoir une autorisation spéciale de l’auteur pour diffuser son œuvre sur le réseau. Ceci peut paraître une contrainte importante. Cependant, dans le préambule de ce traité, l’OMPI rappelle que le droit d'auteur fait partie de la démocratie. Il faut que la société maintienne un équilibre entre les droits des auteurs et les intérêts du public plus particulièrement en matière d'éducation, de recherche et d'accès aux informations.
Ce traité a été signé par 157 états. C’est ensuite à chaque état signataire de faire en sorte que sa législation comporte des procédures permettant une action efficace contre tout acte portant atteinte aux droits couverts par le traité. Cependant, les législations nationales peuvent prévoir des exceptions ou des limitations au droit d’auteur, en particulier dans les bibliothèques.
Le Parlement européen a proposé une directive (Com 97 628) en juin 1998 sur l’harmonisation de certains aspects du droit d’auteur et des droits voisins dans la société de l’information. La première ébauche limitait de façon drastique la diffusion de l’information numérisée en faisant une exception en faveur des handicapés visuels et auditifs.
En effet, la technique informatique veut que le document soit copié sur l’ordinateur voulant y accéder. La loi protège toutes copies d’une œuvre. Ainsi, la consultation d’un document numérisé devenait payante alors que la consultation d’un document papier dans n’importe quelle bibliothèque se fait librement.
L’interassociation des bibliothécaires, documentalistes et archivistes (ABCD) a demandé aux membres français du Parlement européen d’intervenir pour que des amendements, " garantissant un usage normal et individuel des documents numérisés dans les bibliothèques publiques et universitaires et les centres de documentation ", soient adoptés. Il s’agit d’un dispositif légal d’exception de perception des droits pour les bibliothèques à vocation de lecture publique, d’enseignement et de recherche. Elles pourront ainsi légalement effectuer des copies d’archives, offrir une libre consultation de leurs documents et en proposer le prêt à leurs usagers ainsi qu’à d’autres bibliothèques.
L’ECUP (European Copyright User Platform) a publié deux tableaux proposant des types d’autorisation d’accès selon le type de bibliothèque, le type d’accès et le type d’utilisateur [ECUP-1-98], [ECUP-2-98].
Tout d’abord, il propose une distinction entre les documents électroniques produits par l’éditeur et les documents électroniques numérisés par la bibliothèque. Ensuite il définit quatre types de bibliothèques : les bibliothèques nationales, les bibliothèques universitaires et scolaires, les bibliothèques publiques et les autres bibliothèques et centres documentaires. Enfin il donne six catégories d’accès : les activités internes de la bibliothèque, les services accessibles sur place par les usagers inscrits à la bibliothèque, les services accessibles à distance par les usagers inscrits, les services accessibles sur place par les usagers non inscrits, les services accessibles à distance par les usagers non inscrits et les groupes spécifiques d’usagers.
Quel que soit le type de bibliothèque, pour sa gestion interne, l’ECUP propose l’autorisation de stockage électronique permanent, l’indexation, une copie d’archives et la numérisation des documents non produits par celle-ci.
Les usagers inscrits à la bibliothèque sont autorisés à consulter sur place le texte intégral et peuvent copier un nombre restreint de pages sous forme électronique ou sur papier. Pour les accès à distance, les autorisations sont différentes selon le type de document. Pour les documents électroniques produits par l’éditeur, l’usager ne peut consulter qu’une page. Avec une licence il peut consulter le texte intégral et le copier sous forme électronique ou sur papier, la transmission électronique est payante quel que soit le type de bibliothèque. Pour les documents électroniques numérisés par la bibliothèque, l’usager peut consulter le texte intégral et copier un nombre restreint de pages sous forme électronique ou sur papier. La transmission électronique n’est pas payante pour les bibliothèques publiques.
Les usagers non inscrits ne peuvent accéder à distance à aucune bibliothèque. Ils sont autorisés dans les bibliothèques publiques à consulter sur place le texte intégral et peuvent copier un nombre restreint de pages sur papier.
Des groupes spécifiques d’usagers sont autorisés, dans les bibliothèques universitaires et scolaires et dans le quatrième type de bibliothèque (autres bibliothèques et centres documentaires) pour les documents électroniques numérisés par la bibliothèque, à consulter le texte intégral, le copier sous forme électronique ou sur papier et à le transmettre électroniquement. Pour les documents électroniques produits par l’éditeur, il faut une licence et la transmission électronique est payante.
L’ECUP essaye avec ces propositions de satisfaire à la fois les auteurs qui veulent être rémunérés et les bibliothécaires qui veulent garder un accès libre aux documents pour les usagers.
Le responsable d’une bibliothèque numérique se doit de respecter les droits d’auteur définis par le pays d’origine de l’œuvre numérisé. Actuellement plusieurs solutions connues sont utilisées pour les respecter.
Tout d’abord, certains documents électroniques ont un nombre limité d’accès simultanés. Ceci a été pris en compte dans la programmation des sites diffusant de tels documents. Le programmeur code " en dure " le nombre de personnes admises [SAMUELSON98].
Ensuite, certains documents peuvent être consulté librement mais l’impression doit être contrôlée. Les sites ont alors deux solutions : soit empêcher simplement l’impression, soit compter le nombre d’impression effectuée et rémunérer l’auteur selon cette quantité.
Enfin certains documents ne doivent pas être lisible gratuitement. L’utilisateur peut lire le résumé librement à l’écran et ensuite imprimer le texte intégral. Le nombre d’impression est compté et permet de connaître la redevance à verser au CFDC (Centre Français de Droit de Copie).
Les problèmes de respect des droits d’auteur sont maintenants résolubles, bien que des solutions plus simple peuvent être encore recherchées. Cependant ce n’est pas la seule contrainte qui s’applique à de telles bibliothèques. L’aspect social ne doit pas se perdre. Mais les utilisateurs doivent aussi de leur côté changer de comportement et l’évolution du métier de bibliothécaire est inévitable.
Dans les bibliothèques numériques, le contact humain n’apparaît plus. Le lieu de rencontre qui était les bibliothèques publics disparaît.
Cependant, des outils sont développés pour faire face à ce manque. Ainsi certains permettent que les utilisateurs " se rencontrent " et se parlent sur un site prévu à cet effet comme le Cafe ConstructionKit [ACKERMAN95]. Les utilisateurs peuvent aussi communiquer avec le bibliothécaire par messages électroniques ou par vidéoconférence. Cette technique ne peut être utilisée actuellement que sur des distances très courtes.
Pour accéder à une bibliothèque numérique, l’utilisateur doit connaître un minimum l’outil informatique. Ce qui n’est pas encore à la portée de tout le monde, alors que les bibliothèques sont ouvertes à tous. Par contre, les handicapés qui pouvaient avoir certaines difficultés pour accéder aux bibliothèques sont avantagés par ce système car ils peuvent consulter de chez eux. De même, ceux qui ont des problèmes visuels peuvent combiner les bibliothèques virtuelles et leurs outils informatiques pour rendre lisibles les documents.
Un dernier avantage pour l’utilisateur est que la quantité de documents est plus grande car les bibliothèques numériques peuvent échanger entre elles alors que dans les autres bibliothèques, l'utilisateur est limité aux documents appartenant à la bibliothèque elle seule.
Face à ces solutions apportées pour maintenir un contact humain, les bibliothécaires doivent envisager leur métier sous un nouvel angle [ENGSHAF95].
Ils vont tout d’abord être intégrés dans des équipes de recherche et développement pour que leurs expériences et leurs connaissances des documents soient prises en compte dans le développement des bibliothèques numériques et des moteurs de recherche.
Ensuite ils vont devenir éditeurs et vont devoir gérer les problèmes de droits d’auteur. Les auteurs pourront publier leur document directement sous forme numérique sans passer par un éditeur habituel.
Enfin, ils auront un rôle d’enseignant et de consultant. Ils répondront aux questions des utilisateurs par messages électroniques ou sur le site prévu à cet effet, ces questions concernant non seulement le fonctionnement des bibliothèques mais aussi les questions habituelles sur des thèmes ou des documents particuliers.
La mise en place d’une bibliothèque virtuelle comporte de nombreuses contraintes. Dans un premier temps, les documents doivent être mis sous forme électronique, puis classés et indexés avant d’être implantés sur une architecture informatique adéquate. A ces contraintes informatiques, s’ajoute l’obligation de veiller à respecter les droits d’auteurs. Au delà des problèmes juridiques posés par les bibliothèques numériques, il y a le changement de comportement social que cela implique tant au niveau des utilisateurs qu’au niveau des bibliothécaires.
Malgré ces exigences, l’apport d’une bibliothèque virtuelle peut être bénéfique dans le sens où les bibliothèques virtuelles permettent aux utilisateurs une grande rapidité d’accès aux documents, un confort de consultation et un plus large éventail d’information grâce aux connexions inter-bibliothèques.
[Ackerman95] Mark S. Ackerman
Providing Social Interaction in the Digital Library, 1995
Proceeding Conference DL95 — Digital Libraries
http://www.csdl.tamu.edu/csdl/DL95
[ADOBE98] Adobe
A propos du PDF, notice d’information sur le type de fichier PDF
http://www.adobe.fr/products/acrobat/adobepdf.html
[AFNOR93] AFNOR
Langage normalisé de balisage généralisé (SGML), norme ISO 8879, systèmes bureautiques, traitement de l’information, 1993
[ALLEN95] Robert B. ALLEN BELLCORE
Navigating and searching in hierarchical digital library catalogs, 1995
Proceeding Conference DL95 — Digital Libraries
http://www.csdl.tamu.edu/csdl/DL95
[BACCON96] Brigitte BACCONNIER
La classification décimale de Dewey et ses applications au CDI, 1996
Rapport de DEA Sciences de l’information et de la communication (pages 7-37)
Ecole nationale des sciences de l’information et des bibliothèques (69100 Villeurbanne)
[BANMIT95] Sujata BANERJEE, Vibhu O.MITTAL
On the use of linguistic ontologie for accessing and indexing distributed digital libraries , 1995
Proceeding Conference DL95 — Digital Libraries
http://www.csdl.tamu.edu/csdl/DL95
[CHANGPAEP97] Chen-Chuan CHANG, Andreas PAEPCKE,
Michelle BALDANO, Luis GRAVANO
Metadata for Digital Libraries : Architecture and Design Rationale, 1997
Publication de l’université de Stanford
[ECUP-1-98] ECUP
Recommandation d’ECUP pour l’utilisation de documents électroniques produits par l’éditeur. 1998
Bulletin d’informations de l’ABF n°178 1er trimestre 1998.
[ECUP-2-98] ECUP.
Recommandation d’ECUP pour l’utilisation de documents électroniques numérisés par la bibliothèque. 1998
Bulletin d’informations de l’ABF n°178 1er trimestre 1998.
[EngShaf95] Mark England, Melissa Shaffer
Librarians in the Digital Library, 1995
Proceeding Conference DL95 — Digital Libraries
http://www.csdl.tamu.edu/csdl.DL95
[FOUREL96] Frank FOUREL
Intégration de la structure du document dans le processus de recherche d’informations 1996
Congès INFORSID’96
[FP98] F. P.
La station Digibook 5600 de I2S, 1998
Article du journal MOS (Mémoires optiques et systèmes) N°166— Page 9
[FURUTA94] Richard Furuta
Defining and Using Structure in Digital Documents, 1994
Proceeding Conference DL94 — Digital Libraries
http://www.csdl.tamu.edu/csdl/DL94/paper/furuta.html
[GAUCHAUST94] Susan GAUCH, Ron AUST, Joe EVANS, John GAUCH, Gary MIUNDEN, Doug NIECHAUS, James ROBERTS
The digital Video Library Sysytem : Vision and Design, 1994
Proceeding Conference DL94 — Digital Libraries
http://www.csdl.tamu.edu/csdl/DL94/paper/gauch.htm
[GLAMIN98] Henry M. Gladney, Fred Mintzer, Fabio Shiattarella, Julian Bascos, Martin Treu
Digital Access to Antiquities, 1998
Communication of the ACM, Volume 41 N°4, Pages 49-57
[HUNEAU97] Jean Marc HUNEAU
Rapport de synthèse de PFE — Serveur de thèses en texte intégral, 1997
http://csidoc.insa-lyon.fr/these
[KRIM98] Mourad KRIM
OmniPage Pro 9.0 traite la couleur, 1998
Article de presse Décision Micro & Réseaux N°358, page 37
[LEHEG98] Philippe Le Hégaret
XML, transparents de présentation, 1998
http://www.inria.fr/koala/XML/koala/xml011098/xmlslide0.htm
[MARCOUX96] Yves Marcoux
Place de SGML parmi les nouvelles architectures documentaires, 1996
texte d'une allocution
http://tornade.ere.umontreal.ca/~marcoux/ottawa/marcoux.html
[MICRO98] Microsoft
XML 1998
site web de description du langage
http://www.eu.microsoft.com/xml
[MOEN98] William MOEN
Accessing Distributed Cultural Heritage Information, 1998
Article de la revue internationale Communication of the ACM Volume 41 N°4, Pages 45-48
[MONY97] Sylvie MONY
Bibliothèque Nationale de France ‘s Audiovisual System, Digital Audio, Video and Photo Consultation in a Library, 1997
publication de la direction de l’imprimé et de l’audiovisuel de la Bibliothèque Nationale de France
[NEBFULL94] Douglas Nebert, James Fullton
Use of the Isite Z39.50 software to search and retrieve spatially-referenced data, 1994
Proceeding Conference DL94 — Digital Libraries
http://www.csdl.tamu.edu/csdl/DL95/papers/nebert/nebert.html
[NURFURU95] NURNBERG Peter, FURUTA Richard, LEGGETT John, MASHALL Catherine, SHIPMAN Franck
Digital Libraries : Issues and Architectures 1995
Proceeding Conference DL95 — Digital Libraries
http://www.csdl.tamu.edu/csdl/DL95/papers/nuernberg/nuernberg.html
[PAEPCHANG98] Andreas PAEPCKE, Chen-Chuan CHANG, Hector GARCIA-MOLINA, Terry WINOGRAD
Interoperability for Digital Libraries Worldwide, 1998
Communication of the ACM, Volume 41, N°4, Pages 33-43
[PAEPCOUS96] Andreas PAEPCKE, Steve COUSINS, Hector GARCIA-MOLINA, Scott HASSAN, Steven KETCHPEL, Martin RÖSCHEISEN, Terry WINOGRAD
Towards Interoperability in Digital Libraries Overview and Selected Highlights of the Stanford Digital Library Project 1996
Publication de l’université de Stanford,
http://www.computer.org/computer/dli/r50061/r50061.htm
[QUATERREPORT98] -,
Quaterly Report Stanford Digital Library Project 1998
Publication trimestriel de l’université de Stanford, période 1 Nov 1997 au 31 Jan 1998,
http://Walrus.Stanford.EDU/diglib/pub/
[ROSNAY98] Joël De ROSNAY
Les bibliothèques virtuelles doivent être plurilingues et transculturelles 1998
Interview
http://www.club-internet.fr/special
[Samuelson98] Pamela Samuelson
Encoding the Law into Digital Libraries 1998
Communications of the ACM avril 1998.
[SELNICK98] Steven Selnick, Dan Borrey
La gestion de documents-images sur internet 1998
Article du journal MOS (Mémoires optiques et systèmes) N°165— Page 40-44
[SHENMUK95] SHEN S, MUKKAMALA R, WADAA A, ZHANG C,
An Interoperable Architecture for Digital Information Repositories 1995
Proceeding Conference DL95 — Digital Libraries
http://www.csdl.tamu.edu/csdl/DL95/papers/browne/browne.html
[SRILAM94] Sargur N. Srihari, Stephen W. Lam, Jonathan J. Hull, Rohini K. Srihari, Venugopal Govindaraju
Intelligent Data Retrieval from Raster Images of Documents 1994
Proceeding Conference DL94 — Digital Libraries
http://www.csdl.tamu.edu/csdl/DL94/paper/srihari.html
[TOCHT94] Klaus TOCHTERMANN
A first step toward communication in virtual libraries 1994
Proceeding Conference DL94 — Digital Libraries
http://www.csdl.tamu.edu/csdl/pubs/klaus/TecRepKlaus.html
[VEERNAV95] Aravindan VEERASAMY, Shamkant NAVATHE
Querying, navigating and visualizing a digital library catalog 1995
Proceeding Conference DL95 — Digital Libraries
http://www.csdl.tamu.edu/csdl/DL95